Motivations behind this space
hello friends,
I thought I'd start my first essay by sharing the motivations behind creating this space. I promise that the next essay will be solely about product operations engineering.
All essays and ideas in this space will be written solely by me, and not by AI.
Motivation 1 - I don't want to lose the ability to think, as it's easy to become lazy with AI
When I started using AI to automatically draft user support emails, I noticed that the more I leaned on AI, the harder it became to produce a coherent thought from a blank page.
AI models are becoming more powerful. Hence, there's a tendency to fully offload thinking, personal thought, and ideation to AI models. It is imperative that you do not do this.
In both my private and professional life, I've seen personal messages (think birthday messages or Slack team messages) clearly written by AI. The problem isn't that the messages are AI-generated, the problem is that you lose all essence of personality and genuineness. As you start becoming more fluent in using AI, it will become obvious who has used AI to replace their thinking and writing versus those who have used AI to assist with their blind spots.
If you understand how LLMs work, you may come to the conclusion that AI is just an average of all humanity. Models from Anthropic and OpenAI are trained by being fed a huge slice of human-written text and asked, over and over, to predict the next word in a sentence. There are billions of examples, along with billions of small corrections made before the models are released to the public. What the model ends up learning is the most statistically likely continuation of any given text. "Most likely" means most common, and hence the default output will be the mathematical centre of everything that humans have already said (i.e. the average of all humanity).
However, this average is not standing still, it's actually rising with each new model release. This is why we feel that new models are "smarter".
Imagine a pyramid representing the quality of work in any field, with many people producing low to average work at the base and a few exceptional people at the top. AI sets a horizontal line across it, and everyone producing work below that line gets a free upgrade.
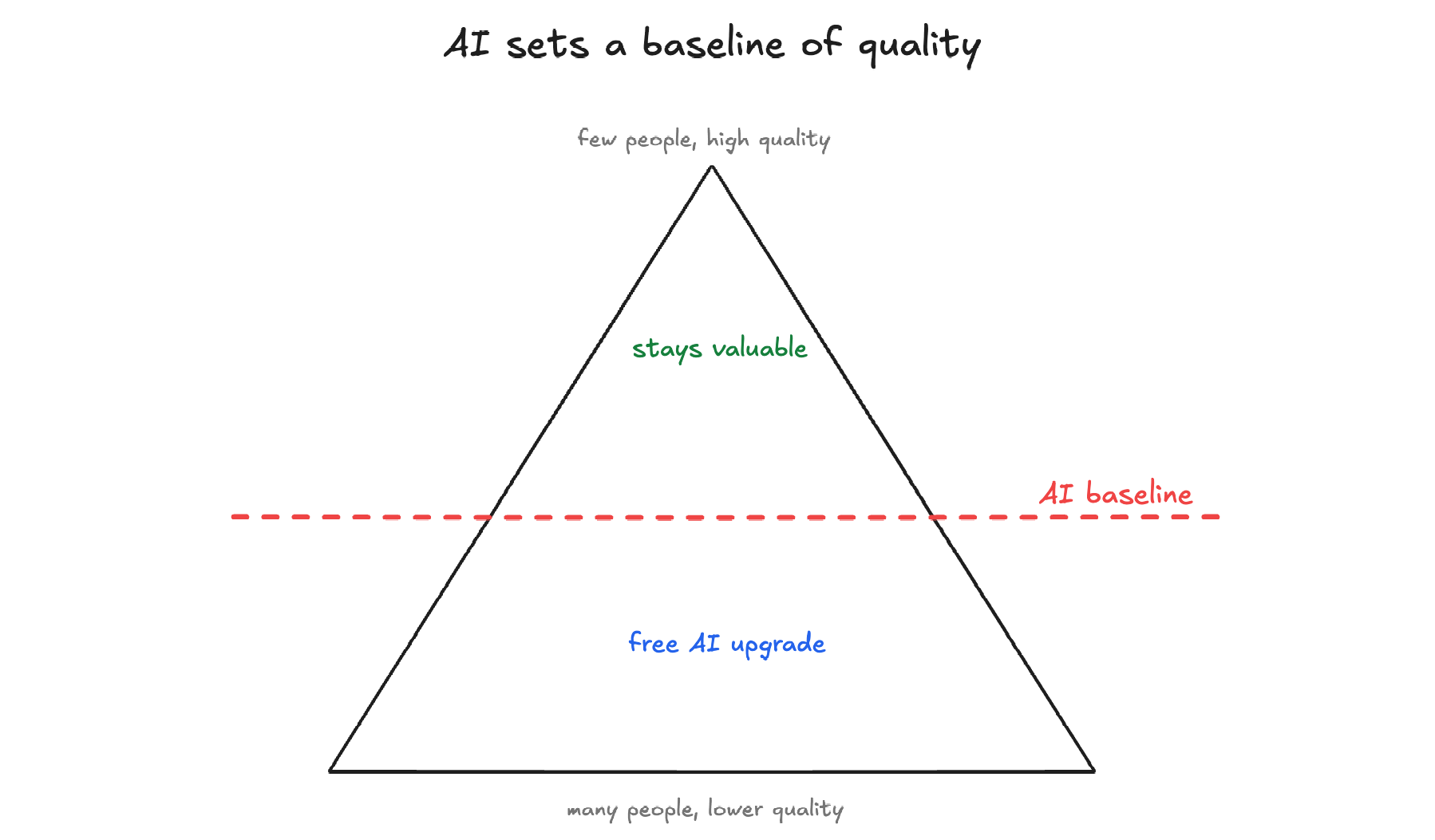
With each new model, the horizontal line gets shifted upwards. For example, what could have been considered a premium user support reply two years ago is now the baseline output from a free chatbot.
So with the reliance on AI for work, the bulk of output gets pulled into an ever-increasing band of competent-but-generic, while the people who can stay above this "AI-average" line become disproportionately valuable.
If you're working in a high-performing organisation or building your own business, being AI-average is no longer enough.
The further down the tree of human knowledge you go, into small, niche, specific branches where the real new domain-specific work happens, the more obvious AI output becomes because the training data thins out and the model has less average to lean on. Just take a look at this example when I asked Gemini 3.1 Pro about prod operations engineering.
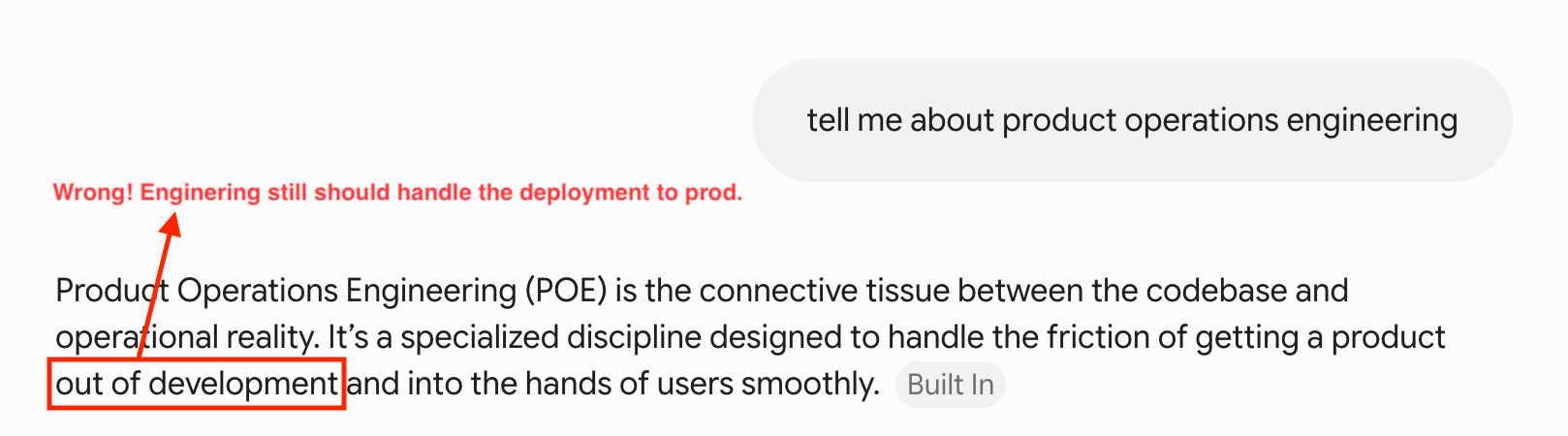
This leads me to motivation 2.
Motivation 2 - Product ops engineering is a new field and I want to help shape it
Product operations engineering barely exists as a defined discipline yet. The term itself is something I'm using because nothing else better has stuck.
I see prodops engineering as architecting AI-native tooling for product operations work. This is very different from the current state of product operations, where people do ops tasks or build small automations. Prodops engineering builds the scalable systems that do these ops tasks while still ensuring human accountability.
There are a number of similar roles out there in the industry from players such as OpenAI, Mistral AI, and YC-backed startups. They go by fragmented names such as AI deployment engineer, AI support engineer, AI product experience, AI operations strategist, etc. All have one thing in common, a requirement to have both the ops and engineering skills to build these systems.
This new role has no real widely agreed set of principles, and no established career path, as no one really knows what it actually means to architect and build AI-native tooling for product operations. That's what makes it exciting for me and why I want to write publicly about it.
I think newer fields get shaped by the people who bother to write things down and share these ideas with like-minded others.
All the vocabulary, the patterns, the anti-patterns, and the assumptions about what's possible often get set early by whoever shows up with a keyboard. I would rather be one of the people contributing to that conversation than wait for someone else to define the terms I'll end up working inside of.
Motivation 3 - Giving back to the community
Almost everything useful I've learned in adjacent fields came from someone's personal blog, a conference talk uploaded by a stranger, or an open-source repo with really good documentation. These were people who took the time to write down what they were learning while they were still learning it.
I've benefitted enormously from that. I recall when GPT-2 was released in 2019 as an open-weight model, there was a blog post I followed which taught me how to do fine-tuning based on Telegram chats with my friend group.
So this space is my attempt to pay that forward.
I likely won't have everything figured out. I'll write about experiments as I run them, the principles as I form them, and the mistakes as I make them. My hope is that if even one person picking up this work a year or two later finds something here that saves them a week of confusion, that's enough.
With that, I'll see you in the next one.
Stay safe, be kind, and above all have fun.
sam dayan.
P.S. i know this site looks very janky with placeholder texts all over. I'll spend some time cleaning it up soon, but for now my P1 is on ensuring that I write useful content for those who subscribe.
disclosures
AI Transparency - Opus 4.7 was initially used with the superpowers plugin to see if this plugin could be applied to writing a blog post (the intent was never to use any of this output, this was just an experiment). Even with the right prompts of what I wanted to write in the design plan, after executing it with subagents, the final output was trash, as it made it sound like every other average blog post out there about AI. I immediately archived the workspace after reading the first paragraph although there may have been some bias which overflowed into this essay. After writing the final essay manually by hand, I passed the essay to Opus 4.7 to fix any editorial errors, ensuring that content was neither added nor removed.